高效用项集挖掘
因为原高效用项集挖掘模式会产生许多低阈值的候选集,所以用效用列表(utility-list)来替代候选集的作用。
样本
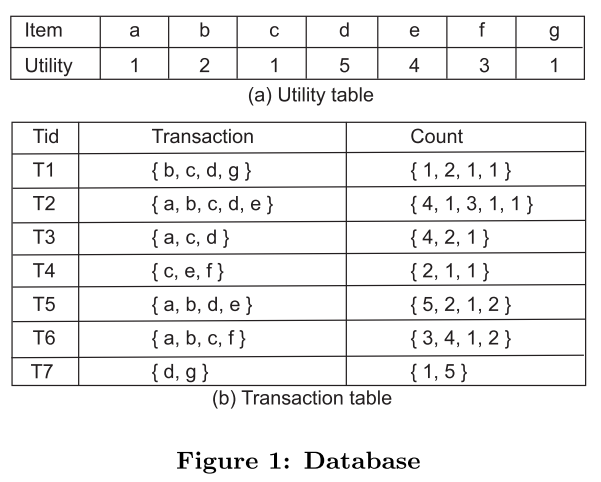
$I = \lbrace i_1, i_2, \dots, i_n\rbrace$ 每个$i$在效用表($utility \; table$)中都存在对应的效用值($utility \, value$)
$X$是关于$i$的集合,叫效用集
定义
$tid$:交易表中的每一项的$id$,且每项都是由$i$组成的超集,交易效用值是所有$i$的效用值的合计
$eu(i)$:$i$的效用值
$iu(i, T)$:$i$在交易表$T_x$项中出现的次数
$u(i, T)$:$u(i, T) = iu(i, T) \times eu(i)$,交易项集$T_x$项中所有$i$7的总效用值和
$u(X, T)$:$u(X, T) = \sum_{i \in X \land X \subseteq T}u(i, T)$,效用集$X$的所有元素$i$在交易表$T$中的总效用值
$u(X)$:$u(X) = \sum_{T \in DB \land X \subseteq T}u(X, T)$,效用集$X$在数据库$DB$中的总效用值
$tu(T)$:$tu(T)$ = $u(T_i, T_i)$ = $\sum_{i \in T}u(i, T)$,在数据库$DB$中所有$i$在$T_x$项的效用值和,例如$tu(T_4) = tu(cef, T_4)$

$twu(X)$:交易项加权效用 $twu(X)$ = $\sum_{T \in DB \land X \subseteq T}tu(T)$,数据库$DB$中包含集合$X$出现在效用集$T_x$项的所有交易项集的总效用值(很关键!!!)
当$twu(X)$值小于设定的阈值,X的所有超集都不是有效项集,因为 $X \subseteq X’$时,有$u(X’) \le twu(X’) \le twu(X) < minutil$
Ps.其实个人认为加上这个是整个算法的前提,因为它解决了之前项集效用值既不是单调也不是反单调的问题,使整个项集又有了排序的可能,再者产生剩余效用项集,构造剩余效用列表(本文亮点)
构造效用列表
效用表是在筛选($twu(x) \ge minUtil$)和排序之后建立的一个新表,这个表中的项集更少(因为删除了低效用值的一元项)
初始化效用列表(一元)
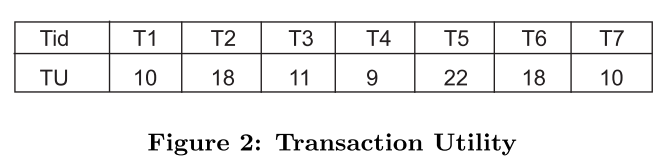
第一遍扫描数据库:生成所有项的$twu(i)$,如果某个项的值低于设定的最小阈值, 那么之后的处理都跳过含有该项的项集,删除低于阈值的项,将大于阈值的项按升序排列,设样例中阈值为30。
第二遍扫描数据库:生成如下图的数据库视图
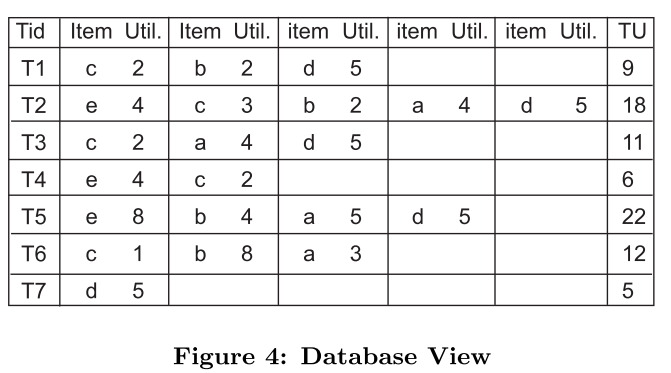
$T/X$:$X \subseteq T$,在T中大于项集X的所有项集都用$T/X$表示(因为之前的已经排好序了),例如$T2 / \lbrace eb\rbrace = \lbrace ad\rbrace, T2 / \lbrace c\rbrace = \lbrace bad\rbrace$,参考上表(枚举树会更容易理解)
$ru(X, T)$:是在各交易项中除去共同前缀项集剩下的项的效用值之和,计算公式为:$ru(X, T) = \sum_{i \in (T/X)}u(i, T)$
补充:
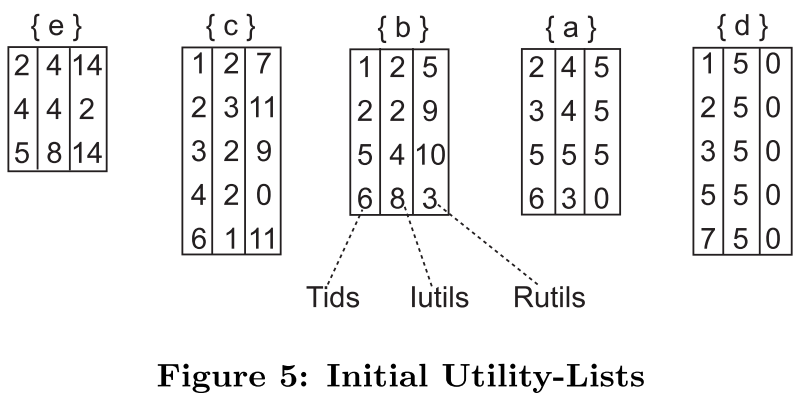
其中集合X的每个效用列表都包含三个属性:
$Tids$:包含集合X的事务集id
$Iutils$:$u(X, T)$,该列的所有值之和就是该项(集)的总效用值U(X)
$Rutils$:$ru(X, T)$,在包含项X的交易项中,所有大于项X的项的U(X)和
二元效用表
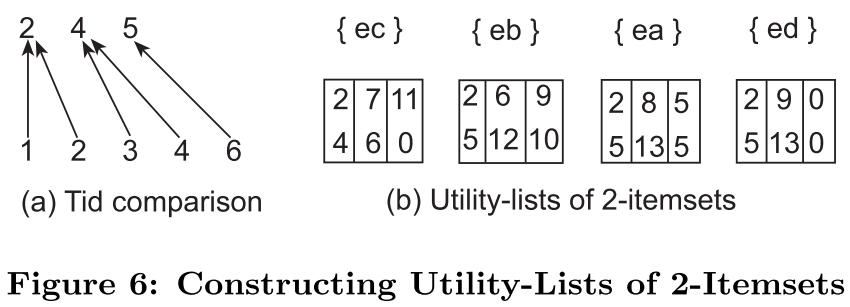
无需再次扫描数据库,
通过比较两个效用列表中的tid,取交集生成新的多元效用列表,
上图(a)第一行是事务表T中包含{e}的项的下标,第二行是事务表T中包含{c}的项的下标(对照Fig.4),
上图(b)其中:
- 每一项的Iutils取两者Iutils的和,Rutils取两者中小的Rutils(对照Fig.5,因为它们都是排好序的,前面的项与后面的项结合,必然是会导致剩余项的效用值减少(Rutils),剩下没合并的项少了)
- Iutils这一列的值相加得到的和就是该项集的效用值
- iutils和rutils这两列的值相加得到的就是该项集的扩展项集的ru值
多元效用表
具体方法和二元计算类似,从二元项集中选取项,如{ec}与{eb}可以生成{ecb},但需要注意的是,计算之间有重叠部分{e}(如下图(a)),所以还要减去u(e, T)(如下图(b)),这里算作是重复计算了共同前缀
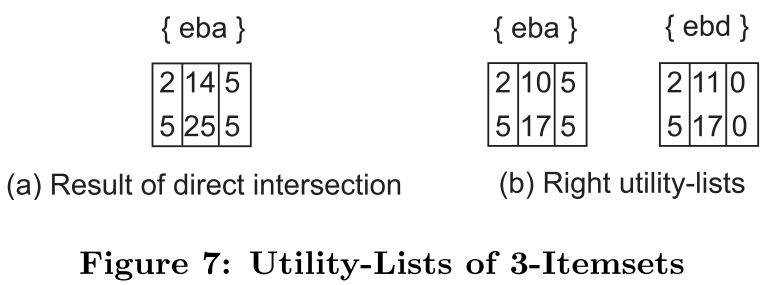
下面是求多元效用表伪代码:

HUI-Miner算法
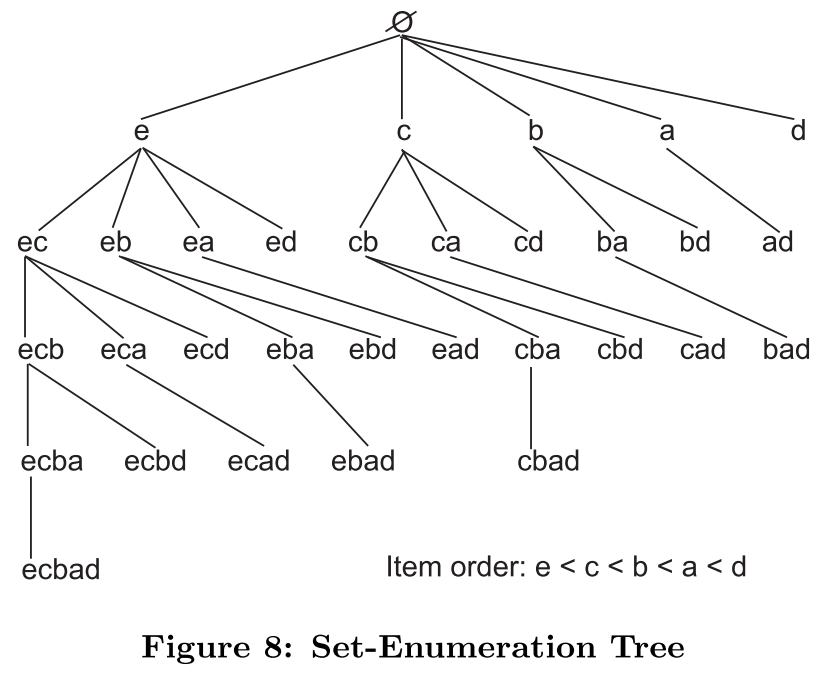
检索空间
使用枚举树结构,每个节点按twu值顺序排序构造方法如下:
- 根节点为空集
- 第一层节点为一元项集
- 从第二层开始,在每个节点末尾依次添加twu值==大于父节点==最后一位元素twu值的元素。(可以简单地认为把后面的节点单个地添加到前面去,因为每层节点twu值都是有序的)
- 重复第三步,直到生成所有节点(每层节点不出现重复节点)
剪枝策略
- 若该项目集对应效用列表所有iutils的总和大于阀值,则该项集为高效用项集。
- 若该项目集对应效用列表所有iutils与rutils的总和大于阀值,则该项目集需要进一步判定。
- 若该项目集对应效用列表所有iutils与rutils的总和小于阀值,则该项目集及其所有扩展都为低效用,对其进行剪枝。
算法实现

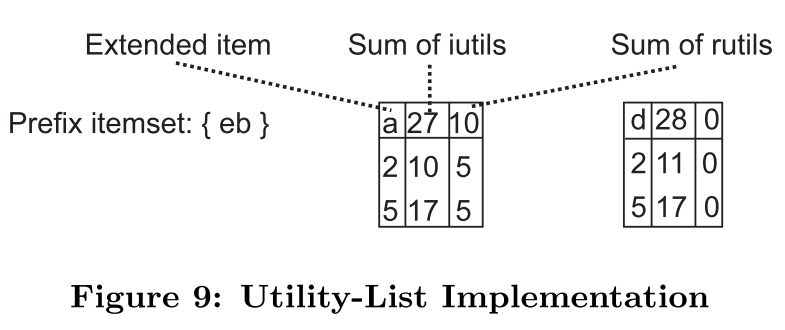
同时为了提高效率,减少对效用列表的扫描次数,集合枚举树中一个节点的所有子节点所代表的项集具有相同的前缀项集。为此,我们将扩展项与前缀项分开存储,Fig.7(b)中的表可以构造成如下图结构:
后记
个人的感理解是因为以前的频繁挖掘模式根据反单调性来生成候选集,后来提出了效用值这个概念去弥补之前的模式对物品的真实价值考量不足的情况;可问题也随之而来,单个项(集)的效用值是非单调的,所以HUI-Miner算法提出TWU(Transaction Weighted Utilities),它具备反单调性,并设计一种数据结构——效用列表(Utility-List),围绕Utility-List展开的效用值计算才是本算法的核心
参考:
1.Mengchi Liu, Junfeng Qu:Mining High Utility Itemsets without Candidate Generation