写在前面:HUI-Miner 是第一个 utility-list based 算法,也是第一个 “one-phase” 类算法,它在原数据集上进行挖掘,进而保证所有生成的项集都是在原数据集中出现过的。此外, utility-list 结构能够对关键信息进行压缩处理,使得算法能够提前剪枝,达到减少 candidates 的目的。目前,有不少学者在继续对 HUI-Miner 算法进行研究,提出各种方法来进一步提高其挖掘效率
Efficient high utility itemset mining using buffered utility-lists
动机
由于 HUI-Miner 算法本身是通过取两个不同的 utility-lists 相交得到新的高阶项集的 utility-list,所以要将所有同一阶层的 lists 一直保留到无法生成新的高阶 lists 才会被释放内存,从内存开支方面来看无疑是巨大的。该算法从减少内存浪费的角度来对 utility list-based 类算法进行改进
定义
大部分定义可以参 HUI-Miner 笔记进行了解,以下只介绍新添加的内容
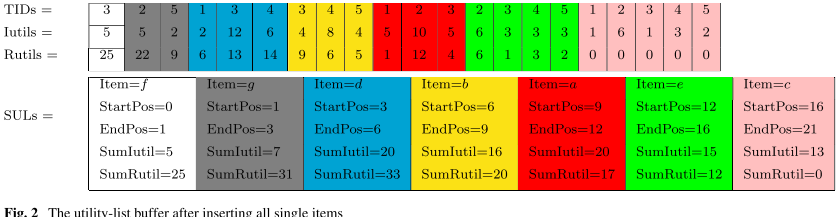
- 效用列表缓冲区(utility-list buffer):类似于一个管道,将所有的 utility-list 都连接起来成一个(下图中第一个子图,由三个列表组成)
- 索引段(index segment):$SUL(X)$ 表示指出项集 $X$ 在效用列表缓冲区中的位置段,用于快速定位。以(X, StartPos, EndPos, SumIutil, SumRutil)元组形式存在,也可以把所有项集的索引段连接在一起形成一个管道(下图种第二个子图,由一个列表组成)
伪代码
Construct Utility-List Buffer Structure
与 utility-list 生成一个个 list 的过程不同,ULB-Miner 是直接将新得到的项集信息继续拼接在原 ULB 存储结构的最后面,其时间复杂度会直接降低为 $O$($n$ + $m$),而 HUI-Miner 的时间复杂度为 $O$($nlog(m)$),其中 $n, m$ 分别表上两个不同的 utility-lists 各自包含的交易项数量

Search procedure
一个递归方法,从低阶项集开始,每一轮扩展单个项形成新的高阶项集

Main procedure

总结
该算法是在 FHM 算法的基础上进行改进(FHM 在 HUI-Miner 的基础上增加了二阶项集过滤环节),从实验数据上来看,ULB-Miner 在大部分的测试数据集种表现都很不错,而且 HUI-Miner 直接加上 buffer structure 其性能表现也是优于 HUI-Miner。同时,作者也指出 utility-list buffer 结构对所有的 list-based 效用挖掘算法都是通用的,为该类算法的研究提出了一个新改进思路。但是与 EFIM 算法相比,性能上还是要差不少,原因在于 list-based 类算法始终需要计算和存储许多元组,而 EFIM 可以直接通过合并缩小数据集,然后投影缩小计算范围。